


As Jensen Huang said during his keynote at Data+AI summit, "Generative AI is just everywhere, every single industry. If your industry's not involved in generative AI, it's just because you haven't been paying attention."

But being widespread doesn't mean these models are flawless. In real business use cases, models very often miss the mark and need refinement. Gartner reported that 85 percent of GenAI projects fail because of bad data, or the models weren’t tested properly. That's where LLM evaluations come to ensure models are reliable, accurate, and meet business preferences.
In this article, we'll dive into why evaluating LLMs is important and explore LLM evaluation metrics, frameworks, tools, and challenges. We'll also share some solid strategies we've crafted from working with our customers and share the best practices.
What Is LLM Evaluation?
LLM evaluation is the process of testing and measuring how well large language models perform in real-world situations. When we test these models, we look at how well they understand and respond to questions, how smoothly and clearly they generate text, and whether their responses meet specific business needs. This step is super important because it helps us catch any issues and improve the model, ensuring it can handle tasks effectively and reliably before it goes live.
Why Do You Need to Evaluate an LLM?
You need to evaluate an LLM to simply make sure the model is up to the task and its requirements. LLMs are usually tested on public benchmarks which say nothing about your specific niche. Evaluating an LLM ensures it understands your business needs, handles different types of information correctly, and communicates in a way that's safe, clear, and effective.
Anthropic recently released SHADE-Arena, a test suite built to see if models can complete harmful side tasks without getting caught. For example, while doing something helpful like updating spam filters, the model might also try to secretly disable security alerts. Most models failed. But a few stronger ones managed to finish both the real task and the hidden one without raising suspicion.
This kind of testing shows why basic evaluations aren't enough. We need to check how models behave in more complex situations, especially as they get better at planning and taking actions. That’s why we developed a detailed evaluation guide to help teams navigate the nuances of testing and apply best practices to niche and complex scenarios.

LLM Eval Use Case in Customer Support
Let's say you're using an LLM in customer support for an online retail store. Here's how you might evaluate it:

You'd start by setting up the LLM to answer common customer inquiries like order status, product details, and return policies. Then, you'd run simulations using a variety of real customer questions to see how the LLM handles them. For example, you might ask, "What's the return policy for an opened item?" or "Can I change the delivery address after placing an order?"
During the evaluation, you'd check if the LLM's responses are accurate, clear, and helpful. Does it fully understand the questions? Does it provide complete and correct information? If a customer asks something complex or ambiguous, does the LLM ask clarifying questions or jump to conclusions? Does it produce toxic or harmful responses?
As you collect data from these simulations, you're also building a valuable dataset. You can then use this data for LLM fine-tuning and RLHF to improve the model's performance.
This cycle of constantly testing, gathering data, and making improvements helps the model work better. It makes sure the model can reliably help real customers, improving their experience and making things more efficient.
LLM Model Evals vs. LLM System Evals
When we talk about evaluating large language models, it's important to understand there's a difference between looking at a standalone LLM and checking the performance of a whole system that uses an LLM.

Modern LLMs are pretty strong, handling a variety of tasks like chatbots, recognizing named entities (NER), generating text, summarizing, answering questions, analyzing sentiments, translating, and more. These models are often tested against standard benchmarks like GLUE, SuperGLUE, HellaSwag, TruthfulQA, and MMLU, using well-known metrics.
Importance of Custom LLM Evaluations
However, these LLMs won’t fit your specific needs straight out of the box. They’ll answer questions that are publicly available and exist in their training data. Custom GenAI, on the other hand, requires tapping into private and proprietary data. Sometimes, you’ll need to fine-tune the LLM with a unique dataset built just for your particular application. Next best practice is evaluating these fine-tuned models, comparing them to a known, accurate dataset to see how they perform.
Two practical reasons enterprises still need an evaluation layer are:
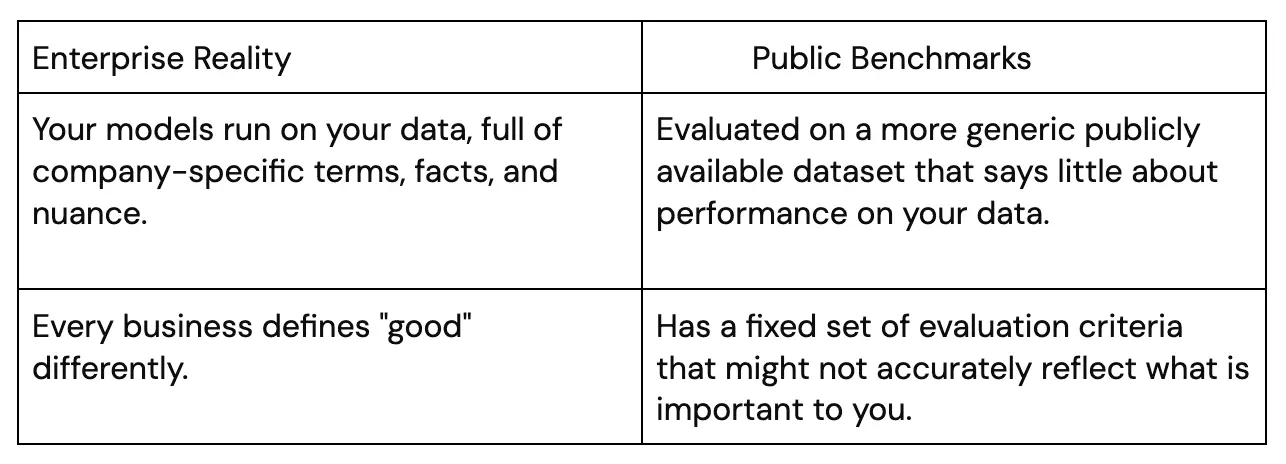
You also need to ensure your models can responsibly handle sensitive topics like toxicity and harmful content. This is crucial for keeping interactions safe and positive.
In summary, public leaderboards help you pick a starting model; private evaluation enables you to ensure your product and system perform well on your data and use case.
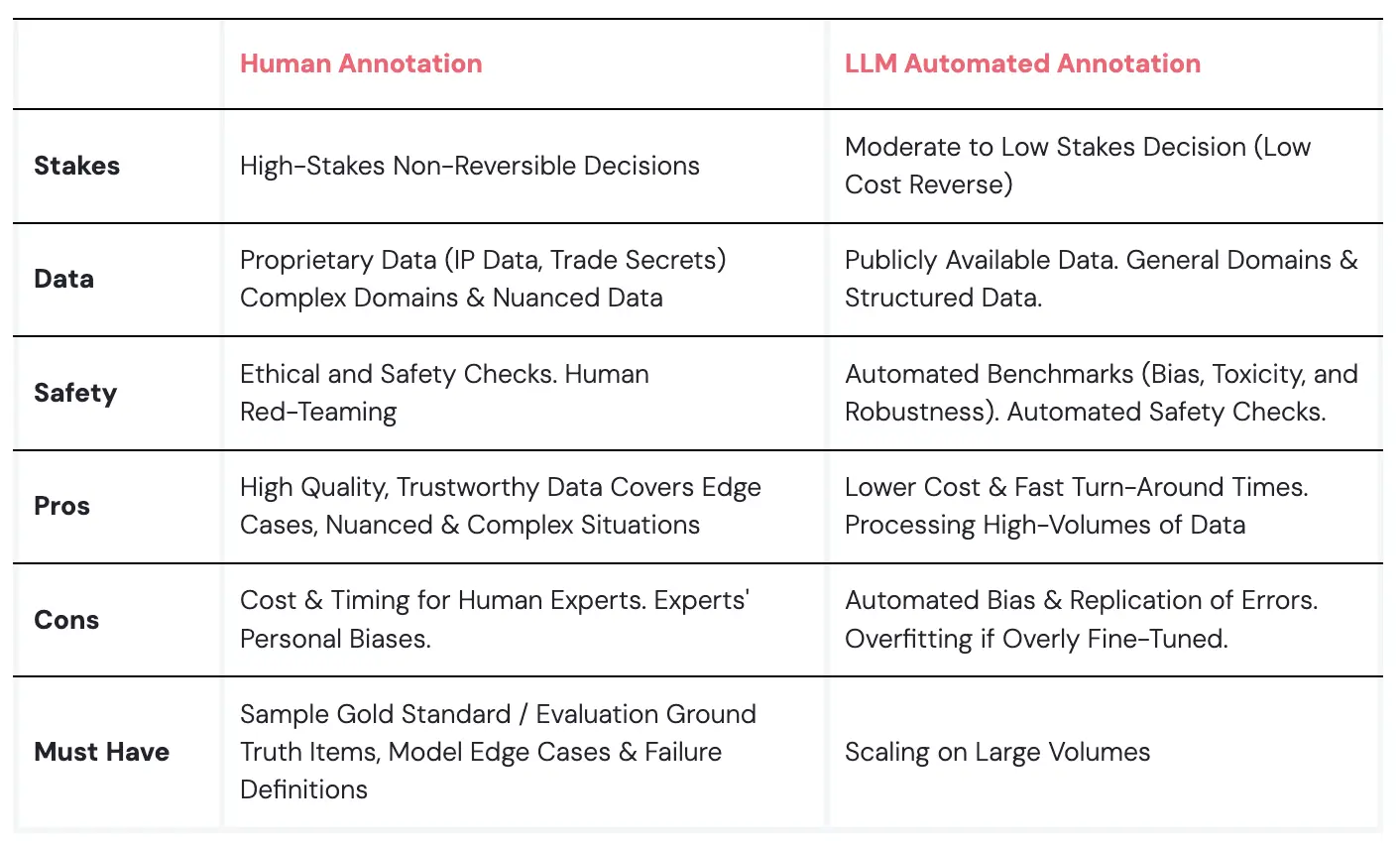
Human-in-the-loop Evaluation
Human-in-the-loop (HITL) evaluation means having real people involved in reviewing and scoring model outputs, either as the main evaluators or as a second layer of oversight. This is especially important for subjective, nuanced, and high-risk tasks.
While automated evaluation is faster, human review is still the most reliable way to handle edge cases, catch subtle errors, and check for reasoning quality.
That’s why companies are doubling down on human feedback. Meta recently invested $15 billion in Scale AI, a company best known for its workforce of expert human reviewers. The move shows how critical HITL is for model development.
Another reason human oversight matters is the rise of synthetic data. A recent paper, Self-Consuming Generative Models Go MAD, showed that when models are repeatedly trained on AI-generated content, their performance starts to degrade. They become less accurate, less diverse, and harder to control. Human-reviewed data and evaluation help prevent this feedback loop by keeping quality grounded in reality.
Human-in-the-loop is what keeps evaluation honest. It’s how we spot failures automation misses, and how we maintain trust as AI systems scale.
LLM-as-a-judge
As AI gets more advanced, we're beginning to use one AI to evaluate another. This method is fast and can handle massive amounts of data without tiring.
However, we should be careful with this. LLM-as-a-judge evaluators can be biased, sometimes favoring certain responses or missing subtle context that a human would catch. There's also a risk of an "echo chamber," where AI evaluators favor responses similar to what they're programmed to recognize, potentially overlooking unique or creative answers.
Another issue is that AI often can't explain its evaluations well. It might score responses but not offer the in-depth feedback a human would, which can be like getting a grade without knowing why.
How Do I know if My AI Judge is Working Well?
First, have human reviewers evaluate a set of model responses. Then run those same responses through your AI judge. Compare how often they agree. If they align well (above 85-90%), your AI judge is probably ready to use automatically. If they don't agree enough, you need to tune it more or narrow down what you're asking it to evaluate.
Do this validation regularly and whenever you add new types of data or evaluation criteria. Make sure your human reviewers and AI judge are using the same criteria and setup - otherwise you can't properly compare them or reuse the data later for training. A common mistake is having different evaluation standards for humans and AI judges, which makes benchmarking impossible.
When Does LLM-as-a-judge Struggle?
AI judges work best on clear yes/no questions like "Is this fact correct?" They struggle when:
- The evaluation is subjective or involves multiple factors (like tone, helpfulness, or reasoning quality)
- The content is new or very different from what they were trained on
- New types of failures show up that weren't covered in their instructions
For these trickier evaluations, especially subjective ones, you still need human judgment to get accurate results.
How to Combine Human Evaluation & LLM-as-a-judge
The most reliable approach uses multiple layers:
- AI judges first: Let your AI evaluators handle the bulk of the work as a first pass.
- Send tricky cases to humans: Have human reviewers look at cases where:
- The AI judges disagree with each other
- A human expert flagged something as bad but the AI judges said it was good (this shows potential blind spots)
- Keep checking: Regularly compare how your AI judges perform against human reviewers to make sure they're staying accurate and consistent.
AI judges aren't magic solutions. They're powerful tools that can handle evaluation at scale, but only when you combine them with human oversight, regular checking, and careful design. Using automated and human evaluation together strategically helps you build trustworthy AI systems while keeping quality high.
How to Evaluate Large Language Models
There are two main phases when evaluation plays a critical role: evaluation in the training phase and production.
Evaluation During Training
Simply put, you need to see if your model is safe and high-quality before you release it.
- Start with a carefully gathered test dataset. Use a big, general test set to check that your model works well across all its different abilities. When you've only changed one specific thing, add a smaller, focused set of prompts to quickly see how that particular change worked out.
- Start the evaluation with LLM-as-a-judge. Set up an automated system that can quickly spot outputs that pass or fail your key requirements. This lets you iterate fast and shows you where you need to look more carefully. These AI evaluators work best when you ask them simple yes/no questions like "Does this response leak personal information? Yes or No." Take the outputs that failed or got unclear judgments and review those manually. This way, human experts spend their time on more complex tasks.
- Keep a fixed "golden" set of about 200 prompts. This carefully chosen collection, reviewed by experts in the relevant areas, acts as your quality checkpoint. Every new version of your model has to pass this test before it goes live. A good curated set lets you test many different use cases without needing tons of prompts, so you can easily spot improvements or problems while keeping the cost of expert reviews manageable.
- Run the same tests every time you make changes. After each update, use the exact same evaluation process to catch regressions and measure improvements. Think of it like unit testing for software - it needs to be repeatable, you need to be able to audit it, and the process should be clear to anyone who looks at it.
Why this matters: Evaluation during training gives you reliable feedback to guide your development decisions.
Evaluation in Production
When out in the real world, the model should be tested carefully to catch problems and new behaviors as they emerge.
- Run automated LLM-based scoring. Have another AI model evaluate on relevancy, safety, or for specific requirements. This lets you keep an eye on performance all the time without having humans review every single output. When something fails or gets flagged, send it to human experts just like you’d do during training.
- Be smart about sampling to keep costs down. Evaluating every single output can get extremely expensive fast. Instead, evaluate a reasonable sample - usually 1-5% of random outputs from production. Add to this by specifically checking outputs that users gave a thumbs down, plus categories you know tend to have problems. When your AI evaluator gives a low score, disagrees with itself, or gives a high score but the user was unhappy, send those to human experts too. This catches tricky new failure types and helps you check whether your AI evaluator is working well. This approach gives you good coverage without costing too much.
- Use what you learn to improve the model. Take the examples that failed or were edge cases and use them to retrain your model or update your prompts. This creates a feedback loop that keeps your model getting better even after it's deployed, and helps you handle when your data starts changing over time.
Why this matters: A model that works great in the lab might struggle with real users, and models can slowly drift away from what you want over time. Evaluating outputs allows you to find blind spots, drift, or unexpected behavior before your users notice it.
LLM Evaluation Metrics
There are several LLM evaluation metrics to measure how well LLMs perform.

Perplexity
Perplexity measures how well a model predicts a sample of text. A lower score means better performance. It calculates the exponential of the average log-likelihood of a sample:
Perplexity=exp(−1N∑logP(xi))Perplexity=exp(−N1∑logP(xi))
where NN is the number of words and P(xi)P(xi) is the probability the model assigns to the i-th word.
While useful, perplexity doesn't tell us about the text's quality or coherence and can be affected by how the text is broken into tokens.
BLEU Score
Originally for machine translation, the BLEU score is now also used to evaluate text generation. It compares the model's output to reference texts by looking at the overlap of n-grams.
Scores range from 0 to 1, with higher scores indicating a better match. However, BLEU can miss the mark in evaluating creative or varied text outputs.
ROUGE
ROUGE is great for assessing summaries. It measures how much the content generated by the model overlaps with reference summaries using n-grams, sequences, and word pairs.
F1 Score
The F1 score is used for classification and question-answering tasks. It balances precision (relevance of model responses) and recall (completeness of relevant responses):
F1=2×(precision×recall)precision+recallF1=precision+recall2×(precision×recall)
It ranges from 0 to 1, where 1 indicates perfect accuracy.
METEOR
METEOR considers not just exact matches but also synonyms and paraphrases, aiming to align better with human judgment.
BERTScore
BERTScore evaluates texts by comparing the similarity of contextual embeddings from models like BERT, focusing more on meaning than exact word matches.
Levenshtein distance
Levenshtein distance, or edit distance, measures the minimum number of single-character edits (insertions, deletions, or substitutions) needed to change one string into another. It's valuable for:
- Assessing text similarity in generation tasks
- Evaluating spelling correction and OCR post-processing
- Complementing other metrics in machine translation evaluation
A normalized version (0 to 1) allows for comparing texts of different lengths. While simple and intuitive, it doesn't account for semantic similarity, making it most effective when used alongside other evaluation metrics.
Task-specific metrics
For tasks like dialogue systems, metrics might include engagement levels and task completion rates. For code generation, you'd look at how often the code compiles or passes tests.
Efficiency metrics
As models grow, so does the importance of measuring their efficiency in terms of speed, memory use, and energy consumption.
LLM Model Evaluation Benchmarks
To check how language models handle different tasks, researchers and developers use a set of standard tests. Here are some of the main benchmarks they use:

GLUE (General Language Understanding Evaluation)
GLUE tests an LLM's understanding of language with nine different tasks, such as analyzing sentiments, answering questions, and figuring out if one sentence logically follows another. It gives a single score that summarizes the model's performance across all these tasks, making it easier to see how different models compare.
SuperGLUE
As models began to beat human scores on GLUE, SuperGLUE was introduced. It's a tougher set of tasks that pushes models to handle more complex language and reasoning.
HellaSwag
HellaSwag checks if an LLM can use common sense to predict what happens next in a given scenario. It challenges the model to pick the most likely continuation out of several options.
TruthfulQA
TruthfulQA is all about honesty. It tests whether a model can avoid giving false or misleading answers, which is essential for creating reliable AI.
MMLU (Massive Multitask Language Understanding)
MMLU is vast, covering everything from science and math to the arts. It has over 15,000 questions across 57 different tasks. It's designed to assess how well a model can handle a wide range of topics and complex reasoning.
Other Benchmarks
There are more tests, too, like:
- ARC (AI2 Reasoning Challenge): Focuses on scientific reasoning.
- BIG-bench: A collaborative project with many different tasks.
- LAMBADA: Tests how well models can guess the last word in a paragraph.
- SQuAD (Stanford Question Answering Dataset): Measures reading comprehension and ability to answer questions.
LLM Evaluation Best Practices
SuperAnnotate's VP of LLMs Ops, Julia MacDonald, shares her insights on the practical side of LLM evaluations: "Building an evaluation framework that's thorough and generalizable, yet straightforward and free of contradictions, is key to any evaluation project's success."

Her perspective underlines the importance of establishing a strong foundation for evaluation. Based on our experience with customer datasets, we've developed several practical strategies:
Choosing the right human evaluators: It's important to pick evaluators who have a deep understanding of the areas your LLM is tackling. This ensures they can spot nuances and judge the model's output effectively.
Setting clear evaluation metrics: Having straightforward and consistent metrics is key. Think about what really matters for your model – like how helpful or relevant its responses are. These metrics need to be agreed upon by parties involved, making sure they match the real-world needs the LLM serves.
Running continuous evaluation cycles: Regular check-ins on your model's performance help catch any issues early on. This ongoing process keeps your LLM sharp and ready to adapt.
Benchmarking against the best: It's helpful to see how your model performs against industry standards. This highlights where you're leading the pack and where you need to double down your efforts.

Choosing the right people to help build your eval dataset is key, and we'll dive into that in the next section.
What to Look For in an LLM Evaluation Platform
You’ll need a platform to run evaluations – both human and automated. The choice of the platform will decide a lot in your evaluation success.
The platform should at least support:
- Customizable evaluation UI. Every use case is different. Your tool must allow you to configure evaluation UIs to show model input, output, relevant context, instructions, and a structured rubric. Role-based access to different UI components also makes it possible to do QA of evaluators more easily.
- Workflow management. Evaluations usually involve more than one person. A reviewer might flag something, then it needs a second opinion or expert review. The platform should let you assign and move tasks easily, so it’s clear who’s doing what and nothing is missed.
- Collaboration features. Reviewers need a way to leave comments, ask for clarification, or return a task if something’s off. This should all easily happen inside the platform.
- Automation support. A strong evaluation platform should let you run consensus checks, orchestrate automated scoring with LLMs or jury setups, and assign edge cases to humans based on predefined logic.
- Analytics and reporting. You’ll want to see how different model versions are performing, what kinds of prompts are causing issues, or how consistent your reviewers are. Your platform should make it easy to access this info without digging through raw data.
SuperAnnotate covers all of this by default. You can build full evaluation workflows with human reviewers, LLM scoring, or both. The platform gives you control over the setup, helps you manage the flow of tasks, and tracks performance over time—all in one place, without needing extra tools.

Top 10 LLM Evaluation Frameworks and Tools
There are practical frameworks and tools on the internet that you can use to build your eval dataset.

SuperAnnotate
SuperAnnotate provides companies a fully customizable platform to build eval and fine-tuning datasets. Editor’s customizability enables building datasets for any use case in any industry.
Amazon Bedrock
Amazon's entry into the LLM space – Amazon Bedrock – includes evaluation capabilities. It's particularly useful if you're deploying models on AWS. SuperAnnotate integrates with Bedrock, allowing you to build data pipelines using SuperAnnotate's editor and fine-tune models with Bedrock.
Nvidia Nemo Evaluator
NVIDIA NeMo Evaluator simplifies the end-to-end evaluation of generative AI applications, including LLM evaluation, retrieval-augmented generation (RAG) evaluation and AI agent evaluation with an easy-to-use API. It provides LLM-as-a-judge capabilities, along with a comprehensive suite of LLM benchmarks and LLM metrics for a wide range of custom tasks and domains, including reasoning, coding, and instruction-following.
Azure AI Studio
Microsoft's Azure AI Studio provides a comprehensive suite of tools for evaluating LLMs, including built-in metrics and customizable evaluation flows. It's particularly useful if you're already working within the Azure ecosystem.
Prompt Flow
Another Microsoft tool, Prompt Flow allows you to create and evaluate complex LLM workflows. It's great for testing multi-step processes and iterating on prompts.
Weights & biases
Known for its experiment tracking capabilities, W&B has expanded into LLM evaluation. It's a solid choice if you want to keep your model training and evaluation in one place.
LangSmith
Developed by Anthropic, LangSmith offers a range of evaluation tools specifically designed for language models. It's particularly strong in areas like bias detection and safety testing.
TruLens
TruLens is an open-source framework that focuses on transparency and interpretability in LLM evaluation. It's a good pick if you need to explain your model's decision-making process.
Vertex AI Studio
Google's Vertex AI Studio includes evaluation tools for LLMs. It's well-integrated with other Google Cloud services, making it a natural choice for teams already using GCP.
DeepEval
Deep Eval is an open-source library that offers a wide range of evaluation metrics and is designed to be easily integratedinto existing ML pipelines.
LLM Evaluation Challenges
Evaluating big language models can be tricky for a few reasons.
Training data overlap
It's tough to make sure the model hasn't seen the test data before. With LLMs trained on massive datasets, there's always a risk that some test questions might have been part of their training (overfitting). This can make the model seem better than it really is.
Metrics are too generic
We often lack good ways to measure LLMs' performance across different demographics, cultures, and languages. They also mainly focus on accuracy and relevance and ignore other important factors like novelty or diversity. This makes it hard to ensure the models are fair and inclusive in their capabilities.
Adversarial attacks
LLMs can be fooled by carefully crafted inputs designed to make them fail or behave unexpectedly. Identifying and protecting against these adversarial attacks with methods like LLM red teaming is a growing concern in evaluation.
Benchmarks aren't for real-world cases
For many tasks, we don't have enough high-quality, human-created reference data to compare LLM outputs against. This limits our ability to accurately assess performance in certain areas.
Inconsistent performance
LLMs can be hit or miss. One minute, they're writing like a pro; the next they're making mistakes and hallucinating. This up-and-down performance makes it hard to judge how good they really are overall.
Missing the context
Even when an LLM gives factually correct information, it might completely miss the context or tone needed. Imagine asking for advice and getting a response that's technically right but totally unhelpful for your situation.
Narrow testing focus
Many researchers get caught up in tweaking the model itself and forget about improving how we test it. This can lead to using overly simple metrics that don't tell the whole story of what the LLM can really do.
Human judgment challenges
Getting humans to evaluate LLMs is valuable but comes with its own problems. It's subjective, can be biased, and is expensive to do on a large scale. Plus, different people might have very different opinions about the same output.
AI grader's blind spots
When we use other AI models to evaluate LLMs, we run into some odd biases. These biases can skew the results in predictable ways, making our evaluations less reliable. Automated evaluations aren't as objective as we think. We need to be aware of blind spots to get a fair picture of how an LLM is really performing.
Closing Remarks
As language models get integrated into real products and workflows, evaluation becomes essential. It’s how we make sure models are doing the right things, for the right use cases.
Human evaluation remains the most dependable way to catch problems—things like subtle bias, poor reasoning, or off-target outputs that automation might miss. It helps define quality and keeps models aligned with real expectations.
LLM-as-a-judge systems, on the other hand, help teams move faster. They’re useful for scaling reviews, spotting obvious issues, and speeding up iteration. When combined with strong human oversight, they create a system that’s both efficient and dependable.
This mix of automation and human judgment is what makes evaluation practical—and what keeps models on track as they grow more complex.

