


In recent years, we keep witnessing a major advance in artificial intelligence, which brings about an ascending implementation of computer vision in real life. Putting all the current hype around autonomous vehicles aside, the autopilot system is alone one of the major accomplishments in machine learning that projects the future reality. It is expected that self-driving cars will become commonplace in the span of 10 years. Chris Gerdes, a professor of Mechanical Engineering at Stanford University and co-director of the Center for Automotive Research at Stanford, is confident that “we can soon give cars the skills of the very best human drivers, and maybe even better than that.”
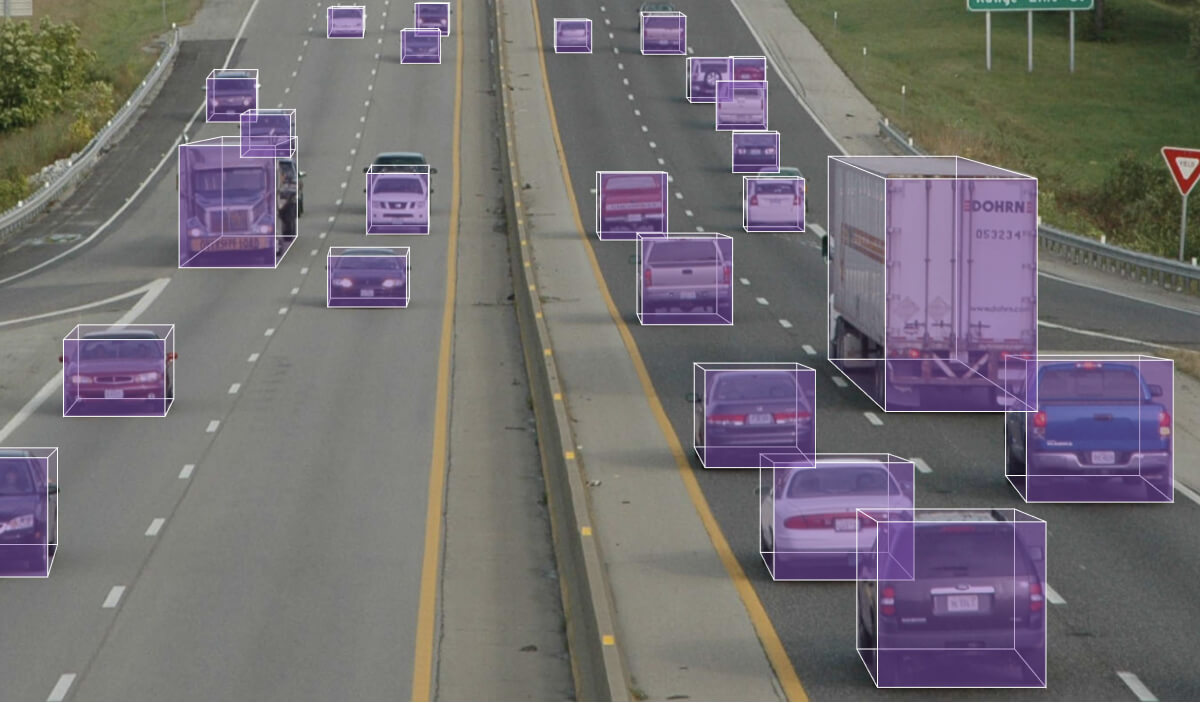
Computer vision is at the core of autonomous vehicle technology. By leveraging object detection algorithms while also using the latest sensors and cameras, autonomous vehicles get to recognize their surroundings, making the entire driving process safer and easier. Yet when companies started testing autonomous vehicles, many challenges emerged for computer vision in them. In this blog, we will cover the following:
- Gathering the training data
- Data labeling
- Object detection for autonomous vehicles
- Road conditions
- Pedestrians
- Stereovision
- Semantic segmentation and instance segmentation
- Multi-camera vision and depth estimation
- How computer vision advanced autonomous vehicles
- What SuperAnnotate has to offer for the automotive industry
- Key takeaways
Gathering the training data
Cars without a human operator require rigorous pattern recognition and a ton of computing power to drive independently. One of the main challenges for AI-powered self-driving cars is the acquisition of training datasets. An artificial intelligence solution is as good as the data it is trained on. Given that, quality datasets and pixel-perfect labeling are of incremental value for the model.
One of the better options for data collection to be used for computer vision in autonomous vehicles is driving around and capturing shots, which can be done either through semi-autonomous driving or by using an artificial model such as the computer game engine. The model has to undergo multiple iterations of camera-generated images for sufficient detection. Keep in mind that the training process has to involve the images of the objects that you want your computer vision model to recognize: things that may appear on the road, street signs, road lanes, humans, buildings, other cars, etc.
Each of these elements is labeled through an individual annotation type: Polyline for lane detection, 3D point annotation for LiDAR, and so forth. A similar variety points to the complexity and vast amounts of data needed to train a model.

Data labeling
The next stage is data labeling, which requires heavy manual labor. For datasets as massive as self-driving cars, data labeling is especially dependent on human effort to identify unlabeled elements in raw images and assign them a class. In the meantime, the labeled data has to be accurately outlined to run successful machine learning projects. Maintaining high levels of precision for large-scale projects is especially challenging. With the increased workforce, there comes increased responsibility for keeping communication open and setting up an effective feedback system so that annotation teams or members within the teams operate in cohesion. For that, we recommend setting up an annotation guideline that roadmaps the annotation process and provides concise instruction to avoid further mistakes and imbalance.
Cohesion, however, should not be confused with the data type. A computer vision model has to be able to make accurate predictions and estimations based on what it “sees” on the road and beyond (regardless of the conditions), which comes down to the need for diverse data input when training a model.
There are multiple ways you could go with data labeling, including in-house, through outsourcing, or crowdsourcing. Whichever you end up choosing, make sure to set up a robust management process to develop a scalable annotation pipeline.

Object detection for autonomous vehicles
Self-driving cars use computer vision to detect objects. Object detection, in turn, takes two steps: image classification and image localization.
Image classification is done by training the convolutional neural network (CNN) to recognize and classify objects. The problem with CNN is that it’s not the best solution for images with multiple objects, as the model is likely not to capture all objects. This is where sliding windows come into play.
As the window slides over the image, it runs each part of the CNN and checks if it resembles any object the model is trained to recognize. If there are objects considerably larger or smaller than the window size, the model won’t detect them. To get that covered, you can use different window sizes for sliding purposes or apply the You Look Only Once (YOLO) algorithm. In this case, the image is run through the CNN only once, as you split it into grids. In the end, YOLO provides predictions based on the probability of each grid cell containing an object: so, no need for several run-throughs.
Now, to point out where the object is positioned on an image, we use the so-called non-max suppression (NMS) algorithm. The NMS algorithm selects the best bounding box for an object based on the highest objectiveness score and the overlap or intersection over union (IoU: calculated by dividing the area of overlap by the area of the union) of the bounding boxes while omitting the rest. The objectiveness score provides the probability of an object being present in the bounding box. The selection process is repeated and reiterated until there is no room for box reduction. In short, NMS can be described as taking the boxes with the lowest probability score and suppressing them.
Let’s use the example below to illustrate how NMS works. Suppose you want your model to detect the car vs. the truck on an image. Here is how you should proceed with box selection using NMS.
- Pick the box with the highest objectiveness score.
- Compare the IoU of the selected box with other boxes.
- Suppress the bounding box with the IoU over 50%.
- Move the next highest objectiveness score.
- Repeat steps 2-4 all over.
The end result, in our case, will be the green boxes with the highest objectiveness score, which is what you want your computer vision model to identify.
Road conditions
Despite having a real-time object detector, there’s a chance that the performance of the computer vision autonomous driving model will vary based on the weather conditions, lighting, and the overall environment that it is in. To avoid any potential accidents related to the previously mentioned factors, autonomous vehicles require large amounts of diverse datasets. Computer vision technologies allow self-driving vehicles to classify and detect different objects; by using LiDAR sensors and cameras and by combining data with 3D maps, autonomous vehicles get to measure distances, and spot traffic lights, other cars, and pedestrians. Let’s take spotting traffic signs as an example. Although computer vision has a real-time object detector, the traffic light or the sign can be dirty, shadowed by a tree, or even rearranged during construction, which can confuse vehicle technology.
Pedestrians
Even though autonomous vehicles can identify pedestrians, they are expected to go beyond and also estimate the pedestrian's poses and expected movements when crossing the street. So an autonomous vehicle has to be more efficient and faster at not only picking up static objects but also pedestrians in motion, which is an additional challenge.

Stereo vision
In order to ensure the safety of the passengers and the vehicle, depth estimation is essential. Although several other tools play key roles, such as LIDAR and camera radar, it is helpful to back them up with a stereo vision. However, this makes room for many other issues, such as the camera arrangement, as the distance between lenses and the sensor can be different for each vehicle, making the depth estimation system more challenging. There is also the issue of misshaping perspectives, as the longer the distance between the camera lenses, the more accurate the depth estimation. However, this creates room for another issue, perspective distortion, which must be considered in the process of depth estimation. Lastly, there is the issue of unparalleled representation, as the cameras in self-driving vehicles can present different images, ones that do not have pixel-to-pixel world representation. This makes an autonomous vehicle’s ability to calculate distances more difficult, as a hardware shift in a pixel can change the representation of an image.
Semantic segmentation and semantic instance segmentation
Semantic segmentation and instance segmentation pose different challenges for autonomous cars. The difference between the two is often confusing: semantic segmentation labels each object in an image (truck, van), while semantic instance segmentation draws the differences between the labeled objects (car1, car2, car3).

The impending problems with the two are performance and confusion. Performance can be a problem because of sensor limitations. Confusion, on the other hand, can be triggered by a handful of external factors, including lighting and shadows, weather conditions, and so on.
Performance and confusion are essential factors to consider when dealing with bigger datasets, as the neural network will be more prone to results generalizations. To that end, the dataset variety and the number of iterations in the process are of uttermost significance to your computer vision project.
Multi-camera vision and depth estimation
Vehicle safety is one of the key metrics for safe-driving cars that cannot be ensured without proper depth estimation. The distance between camera lenses and the object's exact location helps build a secure system and is a pivotal step towards building a stereo vision system.
Perspective distortion
A good distance between the lenses of cameras stimulates effective depth estimation. This, however, can also bring about distortion, which you want to avoid to make accurate calculations.
Non-parallel representation
The difference in pixel accuracy can affect the way the machine calculates the distance. This is especially the case with self-driving cars, as their cameras might not deliver images with the same pixel accuracy. Even the slightest difference in pixels can impact the model calculation to an extent.
How computer vision advanced autonomous vehicles
Despite the challenges mentioned above, it goes without saying how self-driving vehicles advanced through computer vision technology. Let's highlight some of the most essential headways.
3D maps
As autonomous car cameras have the ability to capture images in real-time those same images are used to create a 3D map. By using 3D maps, autonomous vehicle technology can better comprehend the driving spaces and assure a safer driving experience.
Detection of lane lines
One of the most challenging aspects of having a self-driving car is cutting lanes, as once it goes wrong, it could easily lead to an accident. When combined with deep learning models, computer vision gets to use segmentation techniques to identify lines and curves without human/driver involvement.

Airbag disposal
Due to computer vision technology, the data of other vehicles near a self-driving vehicle are continuously being decoded, foreseeing possible crashes or incidents, and releasing airbags just in time to protect the passengers.
Driving in low-light mode
As light conditions differ according to the route and time of the day, an autonomous vehicle must shift between normal and low light modes. Computer vision algorithms can recognize low light conditions and adjust to them by using LIDAR & HDR sensors, FMCW Radars, and other technology.
What SuperAnnotate has to offer for the automotive industry
Companies developing autonomous car technologies heavily rely on machine learning. However, to ensure the success and safety of a model as complex as an autonomous vehicle, they must acquire a solid data annotation workflow with quality management measures and smooth iteration cycles. SuperAnnotate is designed to help companies build super-high-quality data, SuperData, and feed into AI models to get them into production 10x faster. Some of SuperAnnotate's most commonly used tools for autonomous driving are the following:
- 3D cuboids allow you to outline objects in both images and videos while being able to label them on depth, width, and length.
- Polygons offer the ability to perform pixel-cut annotations for precise object detection and localization in images and videos.
- Semantic segmentation is used to divide the image into clusters to classify objects like cars, bikes, pedestrians, sidewalks, traffic lights, and much more in a seamless manner.
- Polyline allows you to annotate line segments to train a lane detection model. It is used to annotate wires, lanes, sidewalks, etc.
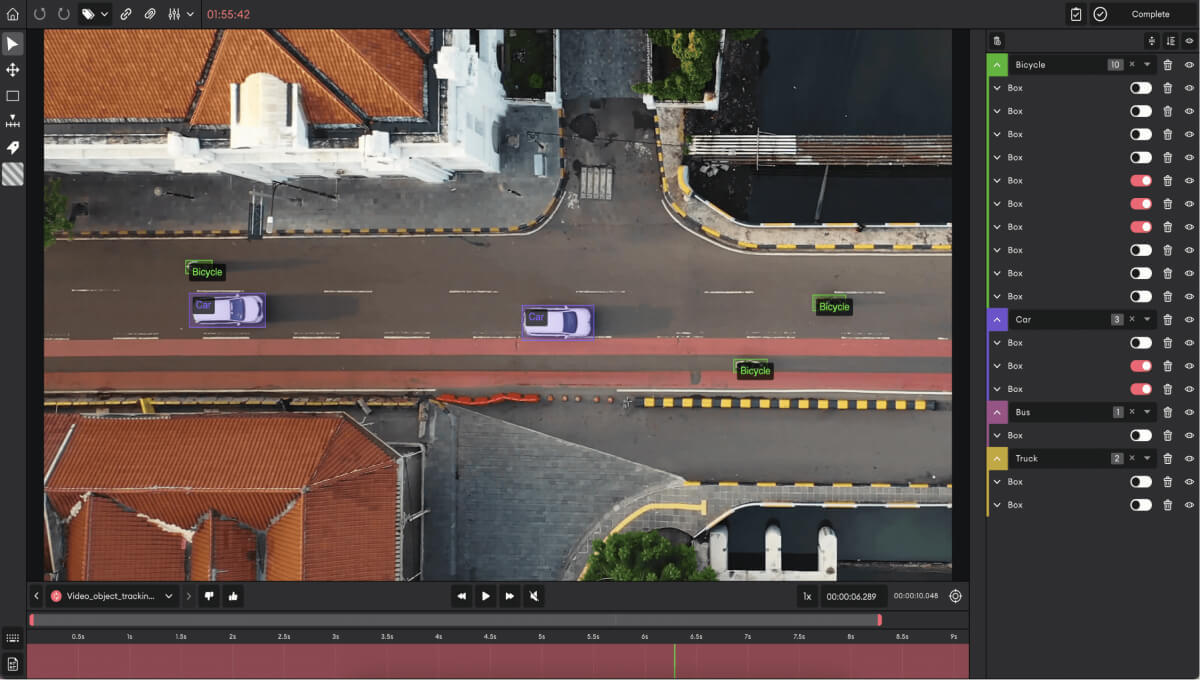
Once you have your data ready with SuperAnnotate, you can check the quality of your dataset with SuperAnnotate’s data curation (Explore) feature. You can either type the queries yourself or use autosuggestions. Autosuggestion makes it easier for you to generate queries. The grid view is one of our commonly used features in Explore that users love. It saves you a significant amount of time as you can easily check all of your images at once instead of looking at each one separately.
Key takeaways
In a day and age where a radio-controlled electric vehicle is not the only automatic vehicle, the artificial intelligence technology in self-driving cars is an unending ocean full of discoveries and rapidly advancing technological tweaks and turns. Yet autonomous cars would have been impossible without state-of-the-art datasets and robust computer vision, which comes down to the need for a consistently expanding workforce and respective challenges for your model to excel.
The main challenges we tracked when training a computer vision model for self-driving cars were the process of data gathering, dataset labeling, object detection, semantic segmentation, and semantic instance segmentation, object tracking for the control system and 3D scene analysis, multi-camera vision, and depth estimation. Which one do you think poses the greatest challenge?