


After the release of ChatGPT two years ago, companies like OpenAI have been pushing the boundaries by adding more data and computing power to enhance AI models. AI researchers globally believed OpenAI would build ever-larger LLMs using unique training techniques like the ones behind their o1 model training.
However, this belief is widely questioned now by the most prominent AI scientists globally. One of them is Ilya Sutskever, who predicts a plateau in AI models’ performance improvement. This phenomenon is increasingly referred to as the “AI data wall” – a point where adding more publicly available data doesn’t significantly improve AI systems.

This plateau, while challenging, highlights a new opportunity for enterprises to tap into their private, domain-specific data that these foundation models haven't been trained on. As Sutskever said, “Scaling the right thing matters more now than ever.”
In this blog post, we’ll understand the concept of “AI data wall,” explore why AI models are hitting that wall, and what enterprises can do to break through it.
What is the AI data wall?
The AI data wall concept emerged when OpenAI’s upcoming flagship model, code-named Orion, had much less performance improvement over its prior models than the performance jump GPT-4 had over GPT 3 (according to OpenAI employees). And it’s not only OpenAI. Google is also finding it hard to score similar performance gains for Gemini as it did last year. The improvement is still there, but it’s not meeting the initial expectations.
Rethinking AI scaling laws
This situation hints at a major challenge in artificial intelligence – AI data wall. AI data wall goes against the common scaling law assumption that AI models will get better as long as they’re fed more data and additional compute power.
“The 2010s were the age of scaling, now we're back in the age of wonder and discovery once again. Everyone is looking for the next thing,” said Ilya Sutskever.
As there’s less and less unused public data for pre-training, AI researchers are heavily speaking out on the limitations of the well-known “bigger is better” philosophy in AI.
Why did we “hit the wall”?
Foundation language models like GPTs are pre-trained on a vast amount of publicly available text and other data from websites, books and other sources. The problem is - there’s a limit to how much you can squeeze that data, and we’re likely very close to that limit.
Sasha Luccioni, researcher and AI lead at Hugging Face, argues a slowdown in progress was predictable given companies' focus on size rather than purpose in model development.
"The pursuit of AGI has always been unrealistic, and the 'bigger is better' approach to AI was bound to hit a limit eventually – and I think this is what we're seeing here," she told AFP.
AI researchers worldwide are trying to find ways to break through this asymptote and find new ways to boost LLMs’ reasoning capabilities.
One workaround has been the use of AI-generated synthetic data, which companies like NVIDIA, Microsoft, and IBM have started using to train their models. While it shows potential for expanding datasets, researchers have found it doesn’t deliver the breakthroughs many hoped for. For example, the new Orion and Gemini models, which were partially trained on synthetic data, have shown limited improvements. In fact, synthetic data has created a new challenge for Orion, causing it to resemble older models in certain ways and limiting its ability to push past previous performance levels.
How can enterprises break through the data wall?
With all these speculations about reaching the limits of publicly available data, the question arises: what’s next for improving AI model performance? The answer could lie in a resource enterprises already have at their fingertips. As Jensen Huang said:
“Every company's business data is their gold mine and there's every company sitting on these gold mines.”
This data isn’t publicly available and, importantly, hasn’t reached its limits. Private and proprietary data is the tool enterprises own to break through the AI data wall and build better AI models tailored to their unique use cases. This data could be related to products, customers, the supply chain, or any data enterprises own and probably have piles of it. The action to take here is to squeeze intelligence and insights out of this data and use it to your advantage.
Our co-founder and CEO, Vahan Petrosyan, touched upon this topic in our recent Series B announcement:
“This plateau presents a unique opportunity for enterprises with access to vast stores of proprietary, domain-specific data that these foundation models haven't been trained on. By leveraging this data, enterprises can gain a significant competitive advantage by building AI products tailored to their specific needs through fine-tuned models, retrieval-augmented generation (RAG), or custom AI agents.”
How SuperAnnotate helps enterprises unlock the AI data wall
One of the biggest challenges in breaking through this data wall is turning raw data sitting in data lakes or warehouses into high-quality, training-ready data – we call it SuperData. It’s widely known that most of the AI development time—often more than 80%—is spent on preparing this SuperData. This is a major bottleneck when companies are trying to develop smarter services and products for their customers.
At SuperAnnotate, we've developed a solution to help enterprises break through this data wall. We provide the essential infrastructure that allows companies to create their own SuperData more efficiently.
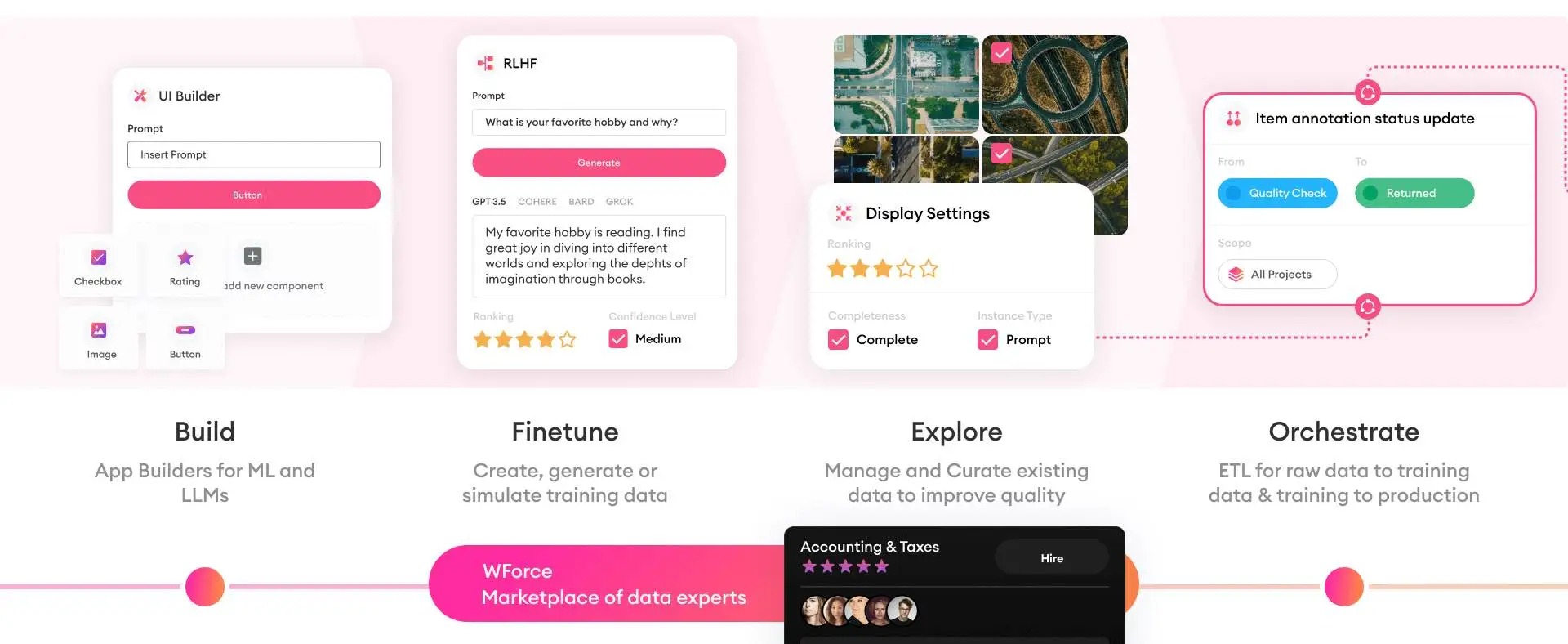
The paths to SuperData vary depending on the use case. For instance, if you’re building a foundation model, you may hit the data wall in pre-training, but you can break this wall in post-training. Or maybe you’re building a smart AI assistant for your product. The initial model may lack domain knowledge, but you can break it by training it on your data. In most of these cases, breaking through requires creating complex, high-quality datasets supported by robust quality control tools, workflow orchestration, and management systems, which we happily provide to our customers.
We’ve worked with companies like Databricks, GumGum, and TwelveLabs, helping them tackle challenges unique to their industries and unlock the full potential of their enterprise data. Whether they’re trying to enhance LLM post-training, improve RAG systems, optimize complex agentic systems, or fine-tune models, the goal remains the same: leveraging proprietary data to drive AI performance.
So the takeaway for enterprises from “Scaling the right thing matters more now than ever” can be – scale your data!
Are we hitting the AI data wall? Have we used all the public data there is? Is AI slowing down, and are we not reaching the skies anymore?
Maybe so. But what we’re not hitting is the SuperData wall. For enterprises, the way forward is clear – transform domain-specific, private, proprietary data into SuperData, and do that with the right data partner.



