


In mid 2024, AI agents became the talk of the tech world – taking on tasks from ordering dinner ingredients to booking flights and appointments. Then came vertical AI agents – highly specialized systems rumored to replace the good old SaaS. But as agents’ influence grows, so does the risk of deploying them prematurely.
An under-tested AI agent can bring a host of issues: inaccurate predictions, hidden biases, lack of adaptability, and security vulnerabilities. These pitfalls confuse users and compromise trust and fairness.
If you're building an AI agent, having a clear roadmap for safely rolling them out is crucial. In this piece, explore why careful evaluation is essential, walk through step-by-step testing strategies, and show how SuperAnnotate helps thoroughly evaluate AI agents and ensure their reliable deployment.
Why Evaluate Agents?
Developing an agent means preparing it for the unpredictable situations it will face in everyday life. Similar to LLM evaluation, we want to ensure agents can handle both common tasks and the occasional curveball without making unfair or incorrect decisions. For example, if the agent screens loan applications, it must treat all applicants equally. If it serves as a virtual assistant, it should understand people’s unexpected questions just as well as the routine ones. By thoroughly testing in advance, we can spot and fix potential issues before they cause real harm.
"Enterprise agents perform best with an eval-first mindset. Success starts with an evaluation process that covers every use case, including edge cases. A core part is a small set of persistent prompts with ground truth outputs that catch alignment drift early and keep performance steady as the agent evolves."
-Julia Macdonald, VP of AI Operations, SuperAnnotate
Evaluation is also crucial for meeting regulations and earning trust. Certain fields, like finance and healthcare, have strict rules to protect people’s privacy and safety. Demonstrating that an AI tool meets these standards reassures regulators, stakeholders, and users that it’s been properly vetted. People are more likely to trust a system when they see evidence that it’s undergone realistic, thorough testing.
Finally, ongoing evaluation helps keep your AI agent in top form as conditions shift over time. Even if it works well in a controlled environment, the world keeps changing. Regular testing lets us catch any performance slowdowns, overlooked scenarios, or subtle new biases. With each update, the agent becomes more effective, delivering reliable results under a wider range of conditions.
Trip Planning Agent Sample Evaluation
Suppose you want an agent to book a trip to San Francisco. What goes on behind the scene?
- First, the agent has to figure out which tool or API it should call based on your request. It needs to understand what you’re really asking for and which resources will help.
- Next, it might call a search API to check available flights or hotels, and it could decide to ask you follow-up questions or refine how it constructs the request for that tool.
- Finally, you want it to return a friendly and accurate response ideally with the correct trip details.
Now let's think about how you'd evaluate this step-by-step.
There are a few things to check. Did the agent pick the right tool in the first place? When it forms a search or booking request, does it call the correct function with the right parameters? Is it using your context, for instance, the dates, preferences, and location accurately? How does the final response look? Does it have the right tone, and is it factually correct?
In this system, there’s plenty that can go wrong. For example, the agent might book flights to San Diego instead of San Francisco. It’s not only important to evaluate the LLM's output, but also how the agent decides on each action. You might find that the agent is calling the wrong tool, misusing context, or even using an inappropriate tone. Sometimes users will also try to manipulate the system, which can create unexpected outputs. To evaluate each of these factors, you can use human feedback( human-in-the-loop), and LLM judges to assess whether the agent's response truly meets your requirements.
How to Evaluate an Agent?
Evaluating an agent needs to be methodical. Below is a practical approach to designing and running agent evaluations.

1. Outline the Agent’s Logging Traces
You can’t evaluate what you can’t observe. Start by setting up logging of traces to capture data over time. For low-risk scenarios, having a subject matter expert review a sample of traces may be sufficient. But to set the foundation for structured evaluation, it is good practice to curate a dataset representative of real-world use that you can use as a basis for your evaluations.
A logging trace is a full record of an interaction, every event from user input to tool calls, reasoning steps, and system responses, all tied to one session, conversation, or agentic workflow. Start logging traces from day one to enable future analysis and debugging.
A complete trace should include original user input and configuration, intermediate reasoning steps, tool calls and outputs, and the final result.
This moves you beyond simple outcome-based evaluation. With traces, you can debug issues, monitor performance, and retroactively investigate new error types as they emerge. Most modern agentic frameworks, for example, LangGraph and CrewAI, support tracing natively.
2. Build a Thorough Golden Prompt Set
For medium and high-risk agents, go beyond simply browsing traces and construct a golden prompt set. This set should reflect both the typical and trickier ways users might interact with your agent. You don’t need an overwhelming number of cases; aim for coverage over quantity.
If you have user data already, this can be done by curating a subset of your traces; otherwise, you will have to spend some time creating a set of prompts.
When selecting which prompts to curate or create, keep the following in mind to build a realistic and representative dataset.
- Cover Realistic Use Cases: Map out the primary tasks users will attempt, but also anticipate edge cases.
- Cover Different Users: Different users will phrase questions and tasks differently. Capture that variety.
- Add Adversarial Prompts: Include tricky or malicious inputs to test system robustness.
3. Pick the Right Evaluation Methods
With a clear view of your agent’s steps, decide how to measure them. Generally, there are two main strategies:
- Compare to an expected outcome
If you can specify the result you want in advance – say, a known piece of data, then you can match the agent’s output against that expectation. This approach helps you quickly see if something’s off.
- Invite human reviewers and involve LLM judges
When there’s no definitive “correct” answer or when you want qualitative feedback (e.g., how natural a response sounds), involve subject matter experts or another language model – LLM-as-a-judge.
4. Factor in agent-specific challenges
Beyond testing the individual pieces, look at how the agent pulls everything together:
- Skill selection: If the agent chooses from multiple functions, you need to confirm it selects the right one each time.
- Parameter extraction: Check that it not only picks the correct skill but also passes the right details along. Inputs can be complex or overlapping, so thorough test cases help here.
- Execution path: Make sure the agent isn’t getting stuck in unnecessary loops or making repetitive calls. These flow-level problems can be particularly tough to track down.
5. Iterate and refine
Finally, once everything is set up, you can begin tweaking and improving your LLM agent. After each change – be it a prompt revision, a new function, or a logic adjustment – run your test suite again. This is how you track progress and catch any new glitches you might introduce.
Keep adding new test scenarios if you spot fresh edge cases or if user behavior shifts. Even if that means your newer results aren’t directly comparable to older runs, it’s more important to capture real-world challenges as they emerge.
Evaluating Agents in Training
While we’ve introduced a general overview of the agent evaluation process, real-world agentic testing is a lot more nuanced and complex. To address the complexity, we should discuss agent evaluation in 2 phases – pre-launch and post-launch. In other words, how to evaluate the agent before people use it, and how to evaluate it after deployment.
Before release, the goal is to understand how the agent performs and where it fails.This stage defines what quality means for your use case and makes sure everyone measures it the same way. It’s also when you decide how results will be reviewed, who is responsible for sign-off, and what thresholds mark readiness for launch.
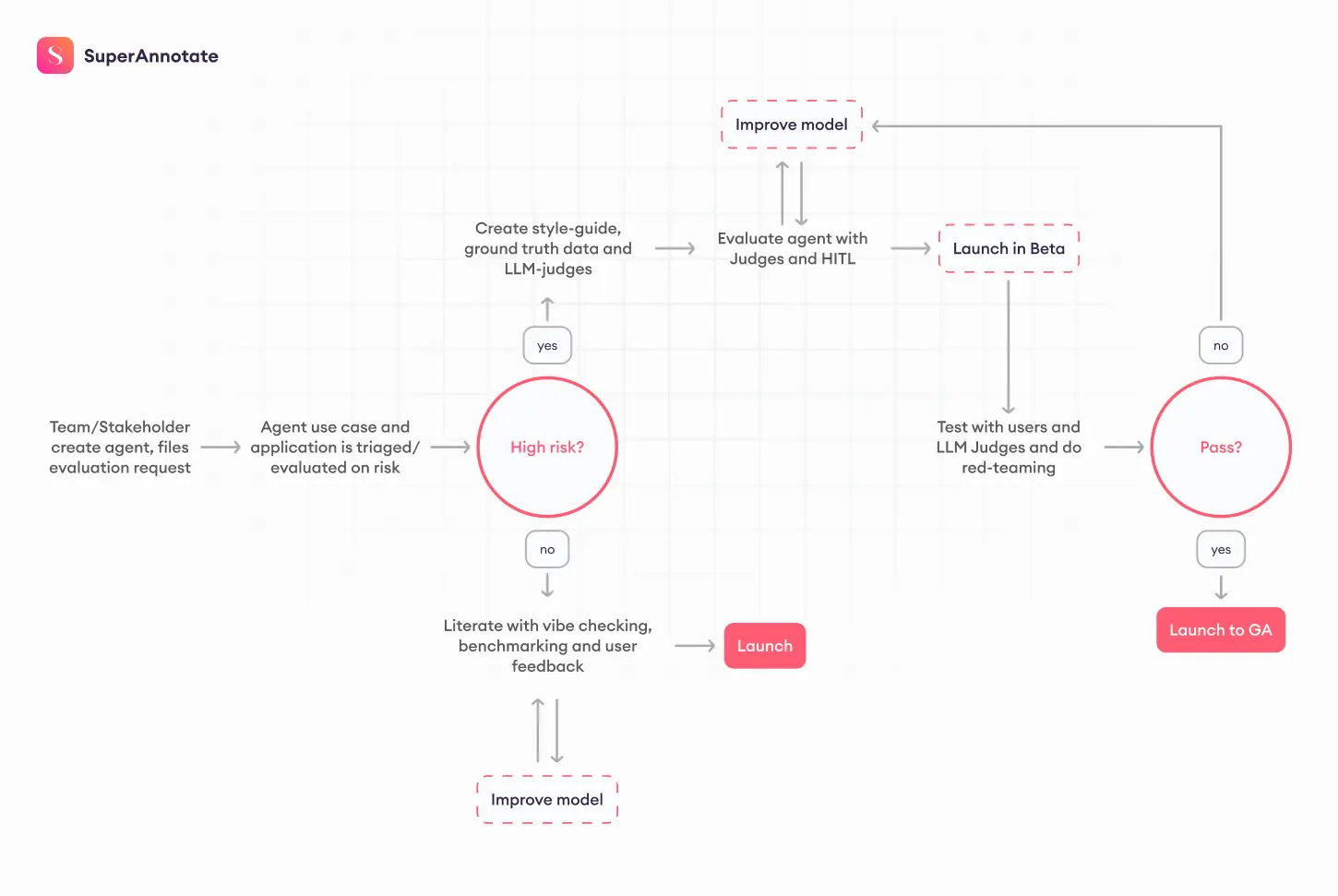
- Define Your Metrics: Choose the measures that show whether the agent works as intended. Decide which ones can be automated and which need human review. Set clear thresholds that show readiness for launch.
- Build Annotator Guidelines: Turn each metric into written instructions. Add examples that show what counts as a pass or a failure. This keeps reviews consistent and helps align future automated checks with human judgment.
- Run a Pilot Round: Review a small batch of data with multiple reviewers. This early stage helps catch unclear definitions and misaligned expectations. Refine the guide until reviewers reach a stable agreement.
- Create a Ground-Truth Dataset: Gather a balanced set of examples that reflect how the agent will be used. Include normal, complex, and challenging cases. This dataset becomes the foundation for benchmarking and training automated judges.
- Build & Calibrate LLM Judges: Use your ground-truth set to prompt-tune and validate LLM judges. Always split the data so that you’re not evaluating on the same examples you used for fine-tuning.
- Iterate and Expand: Run larger evaluation cycles. Loop humans in for low-confidence or “unsure” cases, and spot-check LLM judge performance against your golden set to ensure quality stays high.
Evaluating Agents After Deployment
Evaluation continues after release. Once the agent is in production, new behavior will surface as real users start interacting with it. These patterns often differ from what appeared in test data. Watching how the system performs in its actual environment will help you keep quality stable over time.
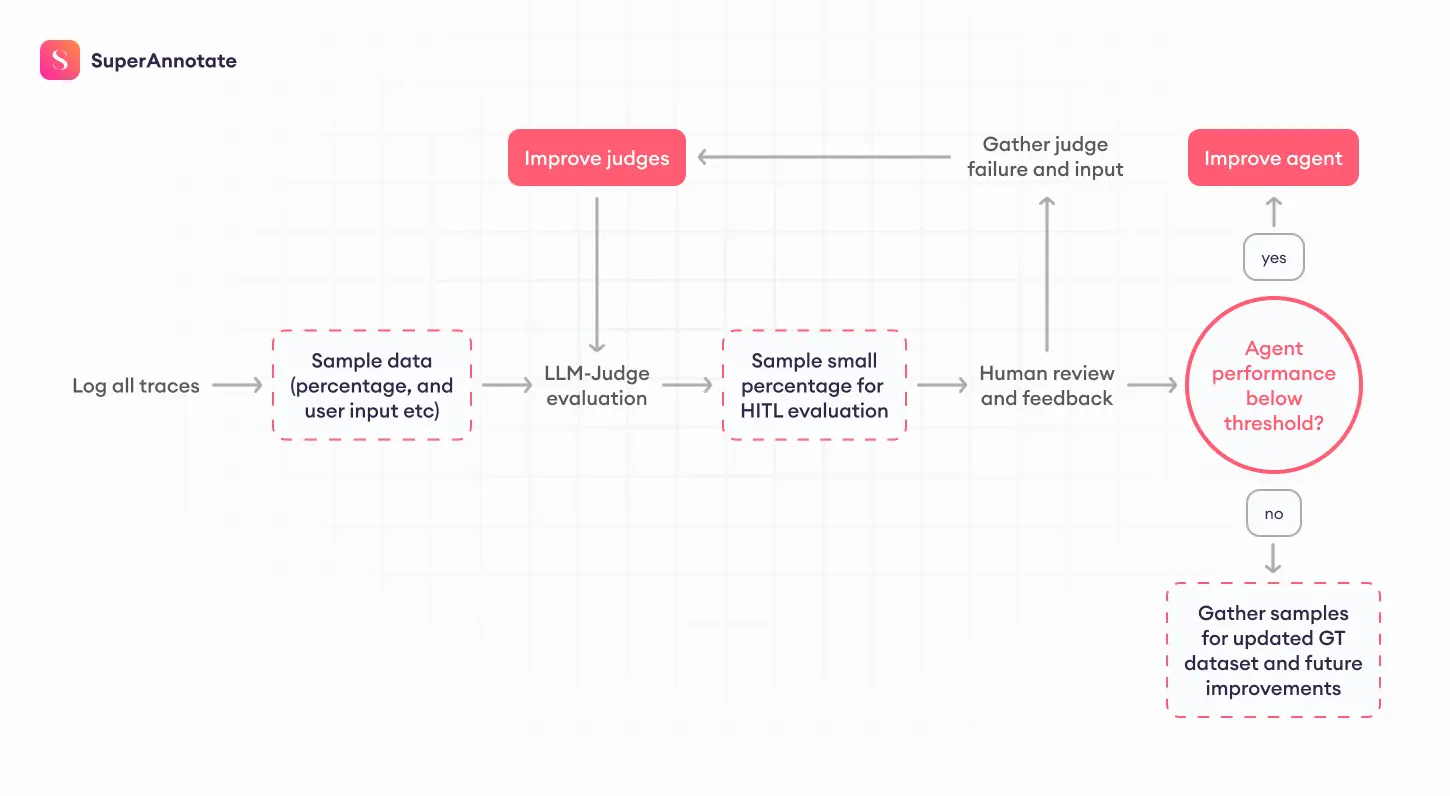
- Monitor with LLM Judges: Put the LLM Judges you built earlier to work on live data. They help you track quality trends at scale and point out where results fall short. Judges can also behave differently when exposed to new data, so keep checking that their scoring still aligns with human expectations.
- Gather User Feedback: If your application collects user input, such as thumbs up or thumbs down, or indirect metrics like repeated or similar queries, include these in your evaluation loop. Compare these observations with the LLM Judge results to see where the agent performs well and where you need adjustments.
- Audit with Human Reviews: Randomly sample a small portion, around one percent, of production traces for manual review.
- Continuously Improve: As new use cases appear or the agent struggles in specific scenarios, add those examples to your test set. Update evaluation guidelines when reviewers find unclear areas. If judges begin to drift or lose alignment, recalibrate them.
The Human Side of Evaluation
AI agent evaluation isn’t just an ML engineering task – it’s a cross-functional effort, bringing human oversight into the data pipeline. Successful teams bring together the right mix of people to turn evaluation from a one-off test into a reliable, ongoing system for decision-making.
Product Managers: Key drivers of alignment: they define metrics, success criteria, and release readiness. PMs make sure everyone understands what “good” means before an AI agent reaches production.
Subject Matter Experts (SMEs): AI agents operate in specific domains, and domain expertise is critical for meaningful evaluation. SMEs help ensure that evaluation criteria reflect real-world expectations and that outputs are usable, safe, and relevant before you ever put an AI agent in front of a customer.
Examples
- Healthcare: Clinicians define clinical accuracy criteria and review outputs
- Marketing/Copywriting: Brand owners ensure tone and style match guidelines
- Enterprise Workflows: Operators validate that AI agents respect workflow context and edge cases
- Executives: Executive involvement is critical to ensure AI agents deliver business impact and operate within acceptable risk boundaries. The right leaders depend on the use case: the CMO for customer-facing experiences and brand voice, the CTO or VP of Engineering for code quality and technical reliability, the CISO for security and compliance, the CFO or Chief Legal Officer for legal and financial exposure, and the CRO for sales impact and productivity. Their perspective helps define what “good” looks like before an agent goes live.
Evaluation data can be distilled into clear, decision-ready summaries for executive sign-off before launch. Ongoing evaluation provides confidence that agents continue to meet “golden prompt set” standards and business KPIs over time.
Evaluate Agents with SuperAnnotate
Designing a robust evaluation program is one thing; operationalizing it at scale is another. The best practices we shared are most effective when you have the right infrastructure, involve the right experts, scale their impact, and continuously improve and adjust as your AI agents evolve. That’s where SuperAnnotate comes in.

Platform
Put Experts in the Loop with Custom UIs: Effective evaluation requires more than just seeing the final output. Subject matter experts need full context, inputs, reasoning steps, tool calls, results, and external data in one place. SuperAnnotate lets you quickly build tailored expert feedback interfaces so reviewers can work efficiently.
Set Up LLM Judges and Automations: Speed and coverage come from combining humans and LLM judges. With SuperAnnotate, you can integrate LLM judges, pre-labeling, and assisted scoring to accelerate throughput while keeping subject matter experts as the quality anchor.
Orchestrate End-to-End Workflows: Evaluation at scale isn’t just labeling; it’s a pipeline. SuperAnnotate’s event-driven orchestration lets you automate work, route tasks to the right experts, manage review stages, and connect evaluation directly to your MLOps stack for continuous monitoring.
“SuperAnnotate enabled us to transform deep medical expertise into scalable, structured ground truth data within our Databricks pipeline, driving 10x evaluation throughput, rapid 5-day iteration cycles, and a new level of alignment between clinical, data, and engineering teams.”
Roman Bugaev, CTO
Flo Health

Services
Expert Network on Demand: Access a vetted global talent pool of 100,000 experts across 100+ domains, from healthcare and legal to enterprise workflows and creative tasks, to get subject matter experts and annotators who deeply understand your use cases and quality standards.
Human–Data Pipeline Design: Partner with our specialists to design and optimize your evaluation pipeline: defining metrics, authoring evaluation guides, calibrating LLM judges, and setting up data flows that integrate with your existing infrastructure.
White-Glove Program Management: Leverage our team’s experience supporting frontier AI labs and top-tier enterprises to run complex, large-scale human-in-the-loop programs. We work hands-on with your team to handle the entire human-data program so your team can stay focused on product and model development.
Agent Evaluation Example with SuperAnnotate
To make this concrete, imagine a basic planning multi-turn agent tasked with organizing an 80s-themed party. We’ll use SuperAnnotate’s platform to run the agent and collect an evaluation dataset based on user’s preferences.
As it gathers user preferences, the agent can ask follow-up questions, recommend different activities, and adjust its suggestions to match what you’re looking for. Here, we’ll focus on four evaluation criteria: relevance, usefulness, factual accuracy, and the diversity of its suggestions.
For the sake of simplicity, we’ll only show one round of conversation in this example. Ideally, the agent would take multiple turns, refining its suggestions and questions until the result is fully aligned with the user’s expectations.

As an example, the agent might propose multiple follow-up questions about music, outfits, decorations, or party games. It might suggest encouraging guests to dress in neon hues, wear leg warmers or shoulder pads, and use eye-catching 80s-themed invitations.

After gathering enough details, here’s a sample plan the agent generates based on those follow-up questions and suggestions.

Collecting evaluation data helps align the agent’s actions with user preferences. Over time, this data-driven refinement process helps the agent offer recommendations that become increasingly relevant, accurate, and diverse.

Final thoughts
Thorough evaluation is the backbone of a trustworthy AI agent. By testing each step of its workflow, gathering real-world feedback, and making precise refinements, you create a reliable system that people can count on. Whether it’s booking flights or handling customer inquiries, a well-evaluated agent consistently delivers accurate, helpful results—ensuring it remains aligned with user needs every step of the way.

Common Questions
This FAQ section highlights the key points about agent evaluation.


